What Broke When I Took an LLM Agent to Production — And the System I Built to Stabilize It
Lessons from shipping a regulated, customer facing LLM agent—and the lifecycle pipeline we built to make improvements measurable, repeatable, and defensible.
April 24, 2026
This week I want to walk you through something we learned the hard way while building a production LLM system in the financial sector.
This wasn’t a prototype or an internal tool. This was a customer facing agent operating under real constraints—multiple regulatory bodies, layered governance, legal oversight, and strict expectations around correctness, explainability, and auditability. Every behavior wasn’t just a UX decision; it had policy and risk implications. Every change needed to be defensible.
I was leading the engineering and architecture for this system, responsible for defining how we would take an LLM based agent from concept to something that could actually operate in that environment. We had a meaningful mandate and a multi million dollar budget to execute against—but the constraints shaped the system more than the budget ever did.
And like most teams working with LLMs at the time, we didn’t start with a mature operational model.
We started by building.
We got an agent up quickly—prompting, retrieval, tool orchestration, and basic guardrails. We focused on getting something functional end to end because that’s what unlocked product velocity and stakeholder buy in. And to be fair, that approach worked initially. We could demo real flows. We could show improvement week over week. It created momentum.
But under the surface, we were missing something fundamental.
Every time we made a change, the system behaved differently. Sometimes better, sometimes worse—but we didn’t have a reliable way to measure that. We were iterating on behavior without a consistent definition of what “good” actually meant, and more importantly, without a way to prove it to anyone outside the immediate engineering loop.
That gap became more visible as more stakeholders got involved. Product wanted faster iteration. Risk and legal wanted guarantees. Governance wanted traceability. And we were in the middle trying to reconcile all of it with a system that, by nature, doesn’t behave deterministically.
So the question shifted from “how do we improve the agent?” to something more fundamental:
How do we make improvements measurable, repeatable, and defensible in a system that changes behavior every time you touch it?
The way we initially approached the problem will probably feel familiar.
We focused on the most tangible parts of the system—prompts, retrieval quality, and tool integration. The workflow was straightforward: make a change, run a handful of examples, inspect the outputs, and iterate. If something broke, fix it. If it looked better, move forward.
It felt fast. It felt productive. And early on, it was exactly what we needed to understand the system’s capabilities.
But that approach doesn’t survive contact with scale or scrutiny.
As the system expanded, the cracks started showing up in predictable ways. Everyone was testing against different examples, so there was no shared baseline. The same class of bugs would resurface because nothing was being formally captured. Fixes in one area would introduce regressions in another, and we often wouldn’t notice until later. Product feedback was subjective. Risk reviews became increasingly difficult because we couldn’t demonstrate coverage or guarantees in a structured way.
The deeper issue was that the system didn’t isolate change well. A small prompt tweak could shift behavior across multiple flows. Improving one metric—like reducing hallucination—could degrade another—like completeness. And because we weren’t evaluating the system holistically, we were effectively optimizing locally and hoping it held globally.
We knew evaluation mattered, but we didn’t stop to design it properly upfront.
Instead, we started building datasets and thinking about evaluation while we were debugging the system. As defects surfaced, we turned them into test cases. As we discovered gaps, we expanded coverage. Dataset design and defect analysis evolved together, in parallel.
That approach eventually got us to a working system—but it came with unnecessary friction.
If I’m being direct about the trade off: we optimized for early speed and paid for it in mid cycle complexity.
In hindsight, one of the highest leverage decisions we could have made would have been to spend a focused block of time—maybe a week—purely on defining evaluation strategy and dataset design before scaling the system. Not to slow things down, but to create a foundation that would have made every subsequent iteration more efficient and more reliable.
The real inflection point came when this approach stopped being “a bit messy” and started actively slowing us down.
Iteration became harder, not easier. Not because we ran out of ideas, but because every change introduced uncertainty we couldn’t quickly resolve. We weren’t just building features anymore—we were trying to reason about a system whose behavior we couldn’t consistently measure, compare, or explain.
At the same time, the level of scrutiny increased—as it should in a financial environment.
Questions started coming in that we couldn’t answer with confidence:
- What exactly changed between this version and the previous one?
- How do we know hallucination rates improved, and where?
- What happens in multi turn edge cases?
- How are we validating compliance with policy constraints?
- Can this system be audited if something goes wrong?
These weren’t hypothetical concerns. They were operational requirements.
And the honest answer was that we didn’t have a system that could answer them cleanly.
That’s when the core realization landed:
We didn’t have a prompt problem. We didn’t have a model problem.
We had a lifecycle problem.
We were iterating on components—prompts, retrieval, tools—but we didn’t have a structured loop that defined expectations, evaluated behavior consistently, tracked regressions, and fed production learnings back into the system.
Which meant every improvement was fragile, and every release carried hidden risk.
That realization changed how we approached the rest of the work.
Instead of asking “how do we fix this behavior?”, we started asking:
What system do we need so that fixing behavior becomes predictable, repeatable, and provable—even under regulatory scrutiny and organizational pressure?
That question is what led to the pipeline we built next.
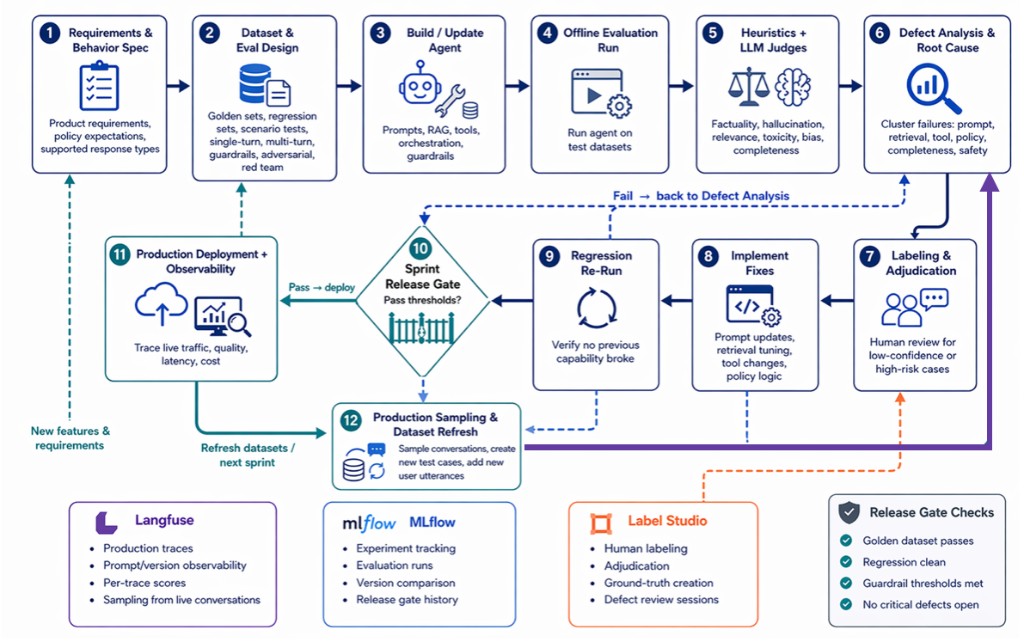
At a high level, this is the system we aligned on.
It’s not complex because we wanted it to be—it’s complex because each part exists to solve a problem we had already hit in practice. Every box represents something that was previously implicit, inconsistent, or missing entirely.
We anchored the workflow around a few core tools to make this operational:
Langfuse for production observability—traces, prompt/version tracking, and sampling real conversations MLflow for experiment tracking, evaluation runs, and comparing system versions over time Label Studio for human labeling, adjudication, and building high-quality ground truth where automated evaluation fell short
Even though I was familiar with these tools individually, using them together as part of a cohesive process was a different challenge. The technical integration was the easy part. The harder part was getting alignment—ensuring everyone understood why each step existed and committing to the discipline required to follow it.
Because this process is painful, especially at the beginning.
You’re asking engineers who are used to deterministic systems to think probabilistically. You’re asking product teams to slow down in the short term to gain confidence in the long term. You’re asking risk and governance teams to engage earlier in the lifecycle instead of acting as a final gate.
That only works if the system is clear.
And this is where the diagram ended up being more valuable than I expected.
It gave the team something concrete to rally around. It made upcoming sprint work explicit instead of reactive. Instead of saying “we need to improve quality,” we could point to specific steps—dataset gaps, evaluation coverage, defect clusters—and assign ownership. It reduced ambiguity, which in turn reduced rework.
It also helped me, personally, as the lead engineer on the team.
A large part of the team came from traditional backend and infrastructure backgrounds—strong engineers, but not “AI native.” They were used to microservices, APIs, and deterministic debugging. This system gave me a way to walk them through not just what we needed to do, but why—why evaluation matters, why regressions are subtle, why datasets are foundational, and why this kind of iteration, while slower upfront, saves a significant amount of time and pain later.
That shift—from reactive debugging to structured iteration—is what made the system start to scale with the team.
Making the pipeline work in the real world
Once we had the pipeline defined, the next phase wasn’t about implementing it cleanly step by step—it was about figuring out how to make it work in the reality we were already in.
And that reality was messy by design.
We had already built a working version of the agent because, quite frankly, we needed something tangible early to get buy in from product, risk, and leadership. In a fast moving environment, especially in the financial sector, credibility comes from showing, not planning.
So while the diagram suggests a neat flow from requirements to datasets to evaluation, what actually happened was that the agent, the datasets, and the evaluation loop were all being built in parallel. We’d ship a capability, observe where it broke, and then turn those failures into structured test cases.
That meant our dataset design was reactive before it became proactive, and while that wasn’t ideal, it turned out to be a pragmatic way to bootstrap the system under time pressure.
In hindsight, we could have saved cycles by investing earlier in dataset design, but without that initial agent, we likely wouldn’t have secured the alignment and momentum needed to justify that investment in the first place.
As we started formalizing evaluation, we quickly realized that scoring outputs wasn’t the hard part—agreement was.
We began with simple labeling workflows, initially in spreadsheets, just to get SMEs and reviewers involved. But as volume increased and the questions got more nuanced, that setup broke down.
We moved to Label Studio, which gave us structure, versioning, and a much cleaner interface for adjudication. And that’s where one of the more interesting dynamics showed up: our automated guardrails didn’t always agree with our domain experts.
We had built conservative filters to block unsafe or non compliant responses, but in practice, SMEs would often say, “this response is fine,” while the system flagged or suppressed it.
That mismatch forced us to rethink how we were tuning guardrails—not as static safety layers, but as domain-aware controls that needed to be calibrated. It wasn’t just about preventing bad outputs; it was about allowing acceptable ones through, which is a much harder problem.
That adjustment alone required multiple iterations and tight collaboration between engineering, risk, and domain experts.
At the same time, we were maturing the rest of the pipeline around this.
Offline evaluation runs became our anchor—we could finally run the agent against a consistent dataset and compare behavior across versions.
We layered in a mix of heuristics and LLM based judges to evaluate responses, not because either was perfect, but because together they gave us a more reliable signal.
Defect analysis became less about fixing individual examples and more about identifying patterns—prompt issues, retrieval gaps, policy mismatches—which made fixes more targeted and scalable.
Every fix fed into regression runs, and over time, that built a safety net that let us move faster without reintroducing old issues.
Tooling played a bigger role than I expected in making this sustainable.
We started with a lot of custom solutions—manual logs, ad hoc tracing, spreadsheets—but that quickly became a bottleneck.
Moving to tools like Langfuse for observability and MLflow for experiment tracking was a turning point. Instead of digging through logs or stitching together context manually, we had structured traces, version comparisons, and a clearer view into how the system behaved in both offline and production settings.
It didn’t just improve debugging—it changed how we thought about iteration. And when we combined that with production sampling—feeding real user interactions back into our datasets—the system started to feel like a true loop rather than a series of disconnected steps.
Looking back, what stands out isn’t any single component of the pipeline, but how all of these pieces had to come together under constraint.
None of it was built in isolation. Each part was shaped by pressure—from timelines, from stakeholders, from the realities of operating in a regulated environment.
And while the process felt heavy at times, it ultimately gave us something we didn’t have before: a way to iterate on an LLM system that was not just fast, but controlled, explainable, and aligned with the expectations of the organization around it.